
Introduction to Supervised Learning

Machine Learning can be broadly divided into different types, and as we covered earlier in our article (type of machine learning & basic workflow), one of the most widely used types is Supervised Learning. It’s the foundation behind many AI systems we interact with every day, from spam filters in our email to recommendation systems on Netflix.
What is Supervised Learning?
Supervised learning is a type of machine learning where a model learns from labeled data. This means the dataset already contains both the input (features) and the output (target/label).
👉 Example: Suppose we have animal images with their names (cat, dog, horse). Here, the images are the inputs, and the names are the outputs. The model learns to map inputs → outputs so it can predict the correct label for new data.
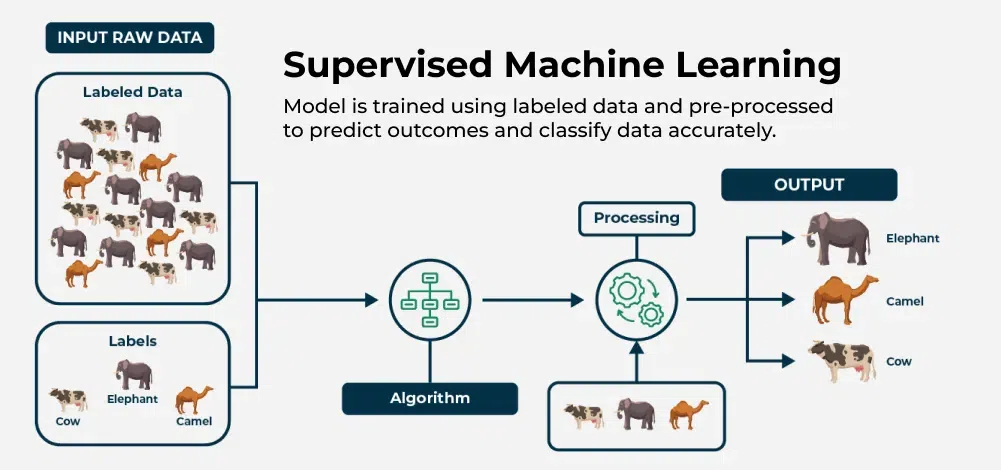
Types of Supervised Learning
Supervised learning can be broadly divided into two main types:
But here’s the key: the type of problem determines the algorithm you should choose. If you want to classify something into categories, you use classification algorithms; if you want to predict continuous values, you use regression algorithms.
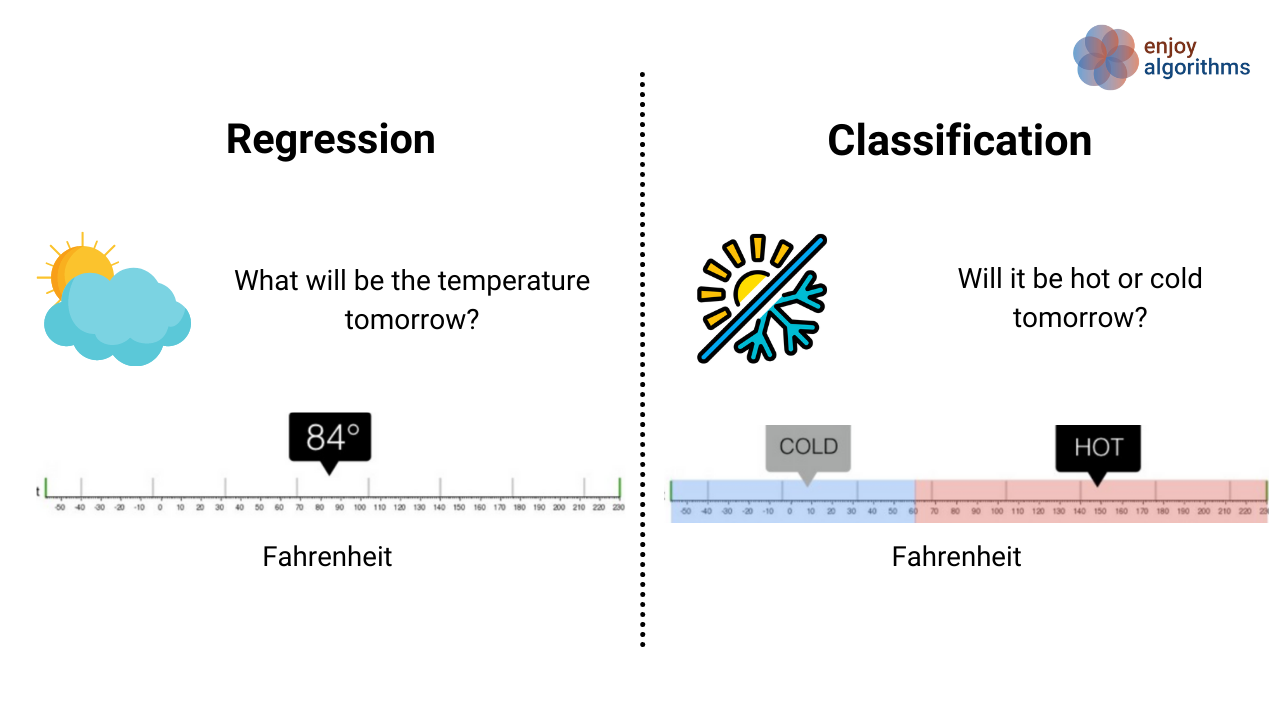
1. Classification
In classification, the goal is to predict a category or class label.
- Example: Predicting whether an email is spam or not spam.
Common Algorithms for Classification:
Logistic Regression → Despite its name, used for classification (e.g., spam or not spam).
Decision Trees → Splits data into branches based on conditions for easy interpretability.
Random Forests → A collection of decision trees that vote for the best class.
Support Vector Machines (SVM) → Finds the best boundary (hyperplane) that separates classes.
k-Nearest Neighbors (kNN) → Classifies based on the majority label of the nearest neighbors.
2. Regression
In regression, the goal is to predict a continuous numerical value.
- Example: Predicting house prices based on size, location, and number of rooms.
Common Algorithms for Regression:
Linear Regression → Models the relationship between features and target using a straight line.
Decision Trees → Splits numerical ranges into regions to predict values.
Random Forests → Uses multiple trees to give more stable numerical predictions.
Support Vector Machines (SVM) → Can also predict continuous values by fitting the best line.
Neural Networks → Can learn non-linear relationships for complex regression problems.
General Workflow of Supervised Learning
No matter which algorithm you use, the basic workflow remains the same:
Collect Data → Gather labeled data (features + target).
Preprocess Data → Handle missing values, outliers, scaling, and encoding.
Split Data → Divide into training and testing sets (commonly 70/30).
Choose the Algorithm → Based on the type of problem (classification or regression), select the most suitable algorithm (e.g., Logistic Regression for classification, Linear Regression for prediction of continuous values).
Train the Model → Use the training data to learn patterns.
Evaluate the Model → Test it on unseen data and measure performance using appropriate metrics (accuracy, precision, recall for classification; MSE, RMSE for regression).
Deploy & Improve → Fine-tune hyperparameters, add more data, or try different algorithms to improve performance.
Applications of Supervised Learning
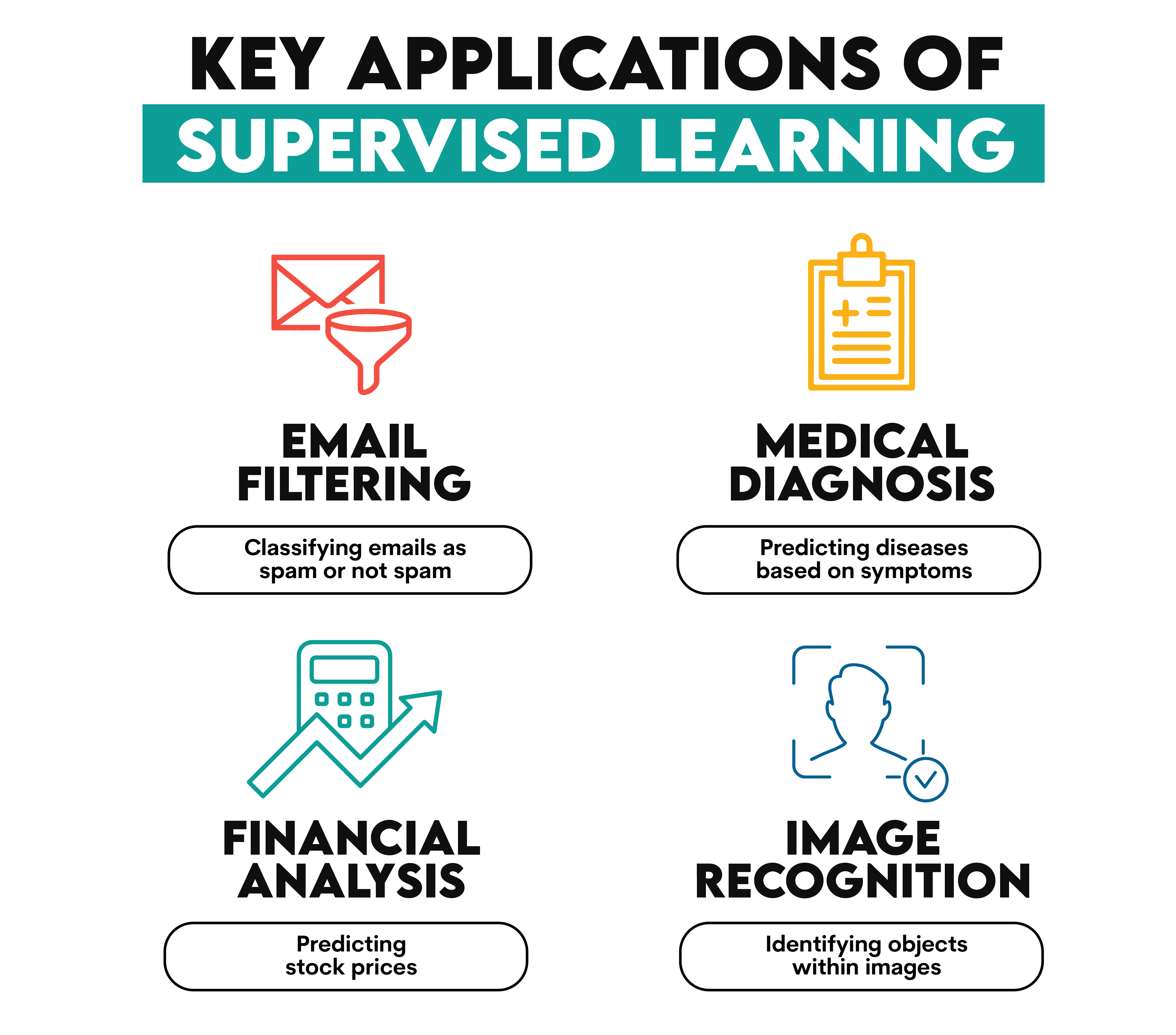
Supervised learning is everywhere around us. Some common applications include:
Spam Email Detection → Classify emails as spam or not.
Sentiment Analysis → Detect whether a review is positive or negative.
Medical Diagnosis → Predict if a patient has a certain disease based on symptoms.
Credit Scoring → Predict if a customer is likely to default on a loan.
Recommendation Systems → Suggest movies, products, or songs based on past preferences.
Conclusion
Supervised Learning is the foundation of many real-world machine learning applications, from email spam detection to predicting house prices. The key lies in understanding your problem first—whether it’s classification or regression—and then selecting the right algorithm to solve it. Once you follow the workflow step by step, even complex algorithms become easier to approach. This structured process not only makes supervised learning understandable for beginners but also helps in building practical, reliable solutions.




