
Apriori Algorithm — Learning Association Rules the Simple Way

As part of our unsupervised learning series today, we will talk about a famous algorithm of an association type. While exploring unsupervised learning, I came across the Apriori Algorithm. At first, it sounded complex, but once I broke it down with real-life examples, it started to make sense.
What Is the Apriori Algorithm? (In Simple Words)

The Apriori Algorithm is one of the most fundamental techniques in data mining and unsupervised machine learning. It is widely used to discover patterns, relationships, and associations between items in large datasets.In simple terms, Apriori helps answer questions like:
“Which items are frequently bought together?”
This makes it extremely valuable in areas such as market basket analysis, recommendation systems, and customer behavior analysis.
Think of it as answering questions like:
What items do people usually buy together?
What actions often happen together?
What combinations appear frequently in data?
This idea is known as association rule mining.
Example: Imagine a grocery store analyzing customer purchases.They notice:
- Customers who buy bread often buy butter, & Customers who buy rice + chicken masala also buy ghee.
This information can help the store t0 create combo offers, improve recommendations, and arrange shelves smartly This is exactly what Apriori helps us do, but at scale.
Key Concepts You Must Know
1. Transaction
A single purchase or event containing multiple items.
Example:
{Milk, Bread, Butter}
2. Itemset
A group of one or more items.
Examples:
1-itemset:
{Milk}2-itemset:
{Milk, Bread}3-itemset:
{Milk, Bread, Butter}
Key Metrics in Apriori
1. Support
Measures how frequently an itemset appears in the dataset.

2. Confidence
Measures how likely item Y is purchased when item X is purchased.

3. Lift
Measures how much more likely two items are purchased together compared to random chance.
Lift > 1 → strong positive association
Lift = 1 → independent
Lift < 1 → negative association
How the Apriori Algorithm Works (Step by Step)
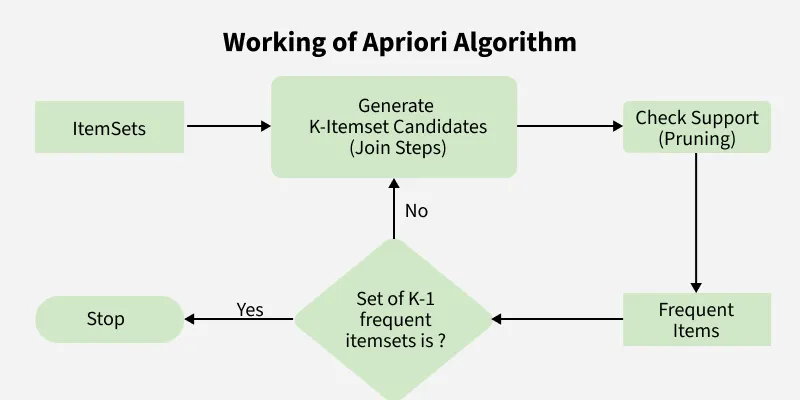
Step 1: Set Thresholds
Before starting, define: Minimum Support and Minimum Confidence. These values control how strict the algorithm is.
Step 2: Identify Frequent 1-Itemsets
Scan the dataset and count how often each item appears.
Example Dataset
| Transaction | Items |
| T1 | {Laptop, Mouse, Keyboard} |
| T2 | {Laptop, Mouse} |
| T3 | {Keyboard, Mouse} |
If minimum support = 50%:
{Laptop}→ 66.7%{Mouse}→ 100%{Keyboard}→ 66.7%
All are frequent.
Step 3: Generate Candidate k-Itemsets
Combine frequent itemsets to form:
2-itemsets
3-itemsets
and so on
Example 2-itemsets:
{Laptop, Mouse}{Laptop, Keyboard}{Mouse, Keyboard}
Step 4: Prune Using Apriori Property
If any subset of an itemset is not frequent, discard the entire itemset.
Example:
{Laptop, Keyboard}has low support → removedSaves computation time
Step 5: Repeat for Higher-Order Itemsets
The process continues until no more frequent itemsets can be generated.
Step 6: Generate Association Rules
From frequent itemsets, generate rules of the form:
Example:
{Laptop} ⇒ {Mouse}
Step 7: Filter Rules by Confidence
Only keep rules that meet the minimum confidence threshold.
Example
{Laptop} ⇒ {Mouse}
Confidence = 100% → Strong rule
Practical Example: Apriori Algorithm (Market Basket Analysis)
We’ll simulate a small grocery store dataset and discover frequent itemsets and association rules.
# installing libraires
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# creating simple dataset
transactions = [
['Milk', 'Bread', 'Butter'],
['Milk', 'Bread'],
['Milk', 'Butter'],
['Bread', 'Butter'],
['Milk', 'Bread', 'Butter'],
['Bread'],
]
# encoding
te = TransactionEncoder()
te_array = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_array, columns=te.columns_)
df
# finding frequest itemset
frequent_itemsets = apriori(
df,
min_support=0.4,
use_colnames=True
)
frequent_itemsets
# generate rules
rules = association_rules(
frequent_itemsets,
metric="confidence",
min_threshold=0.6
)
rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']]

Support tells “how common” . Confidence tells “how reliable”. Lift tells “how meaningful.”
Each row represents an association rule written in the form: IF (antecedent) → THEN (consequent).
For example
(Milk) → (Butter) (row 5)
Support = 0.5 → Bought together in half of all transactions
Confidence = 0.75 → 75% of Milk buyers also buy Butter
Lift = 1.125 → Customers are 12.5% more likely to buy Butter when they buy Milk
This is a strong and useful association.
Some Real World Examples
E-commerce: Recommends products that are frequently bought together to increase sales.
Food Delivery Apps: Identifies popular food combinations to create attractive combo deals.
Streaming Platforms: Suggests movies or shows based on content users often watch together.
Finance: Analyzes spending patterns to offer personalized credit cards or discounts.
Travel & Hospitality: Builds travel bundles like flight + hotel based on common bookings.
Final Words
Apriori doesn’t predict numbers; it reveals hidden buying behavior. That’s why it’s widely used in recommendation systems, combo offers, and business strategy. This algorithm is a cornerstone of association rule mining. While it may not be the fastest algorithm today, it provides a clear conceptual foundation for understanding how machines discover hidden patterns in data.



